As a “Managed Kubernetes” offering, AWS EKS comes with some essential core services, like CoreDNS. (kube-proxy etc.)
CoreDNS is an open source DNS service with Kubernetes plugin for service discovery and by default it’s a DNS server for most of the Kubernetes distribution. Service discovery is actually the main motivation behind hosting a DNS server inside the Kubernetes cluster, otherwise all DNS queries would go to external DNS server. Better to explain with a drawing;
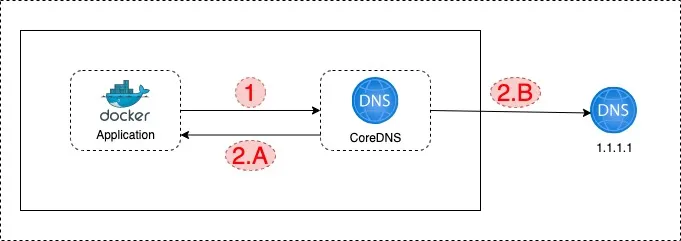
1. Application makes a DNS query
2.A. If the record is a Kubernetes service record, like "application2-internal-service”, CoreDNS responds with service IP address result
2.B. If the record is an external endpoint record like “api.google.com”, then CoreDNS asks the record to the external DNS server
This architecture is done via kubelet, it overwrites “/etc/resolv.conf” file with content below;

Each pod inherits this “/etc/resolv.conf” configuration and thanks to “nameserver” line, each pods goes to CoreDNS service endpoint and CoreDNS pods after that.
AWS pre-defined CoreDNS Configuration
As mentioned CoreDNS comes to EKS cluster out-of-the box in order to make it easy to run an application out of the box. Name of the deployment is “coredns” at “kube-system” namespace.
The manifest separately provided here; https://s3.us-west-2.amazonaws.com/amazon-eks/cloudformation/2020-10-29/dns.yaml
What’s interesting here is the following lines;

So, Although it provides “High Availability” with “replicas:2” and “Auto Healing” thanks to being “Kubernetes Deployment”, it’s missing critical “Auto Scaling” feature, if 2 CoreDNS pods are not enough, it won’t scale up.
Scaling Up CoreDNS pods
During a load test of a client of us (as part of migration preparation), we’ve immediately start seeing DNS query failures at all the pods and quick investigation leaded us to the problem defined above. Under too many requests coming to applications, especially at realistic test besides from main page tests, applications started failing with;

error. Checking CoreDNS pod, they were using quite high CPU.
So the solution sounds easy, adding horizontal autoscaling to CodeDNS pods.
As CoreDNS configured as “Kubernetes Deployment”, it’s quite straightforward to make it auto scalable. What we need to do is attaching HPA (Kubernetes Horizontal Pod Autoscaler) to the Deployment. It can be done with manifest below;

After this critically needed addition, amount of pods are not static 2 anymore but instead scales up based on CPU or Memory requirement, based on our experience, it mostly scales up with CPU metrics.
Brute Force is not our Friend
Although the solution above provides unlimited CPU power based on demand, it actually points out to a problem.
If we simply the relation between application scaling and CoreDNS pods scaling, the graph would be something like this;
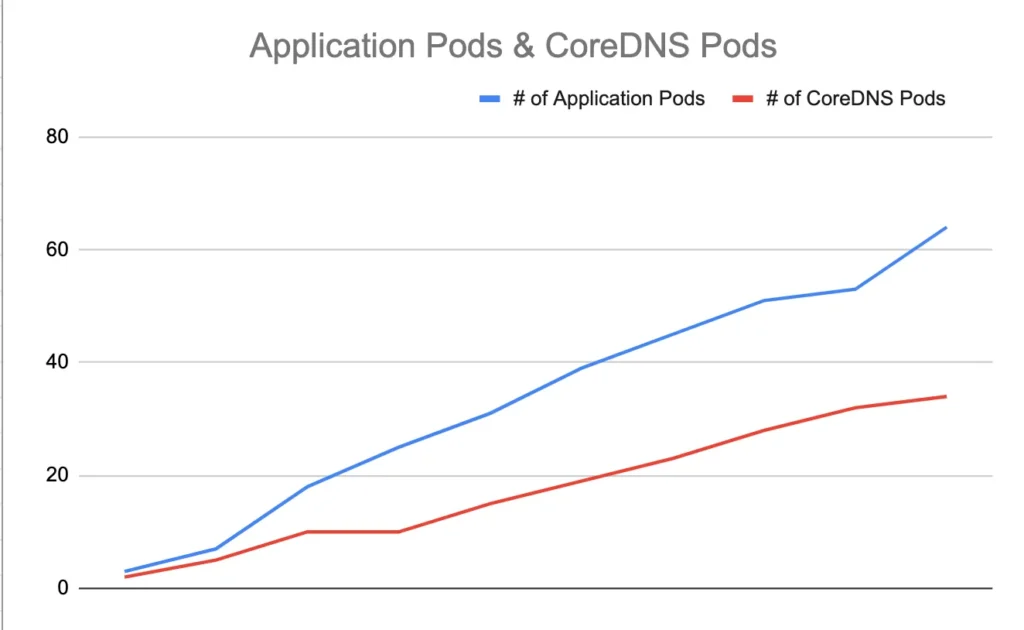
It leads us to a guess that pods are not caching any DNS queries and going to an external system (CoreDNS in this case, by default in EKS) and it causes;
- CoreDNS to scale up linearly with application load
- High latency in database connections, for example, pod first requests
dbname.randomstring.eu-west-1.rds.amazonaws.comthen connects to10.0.0.1(just an example) IP address
So it’s obvious that we should be focusing on caching DNS queries at some level instead of scaling up CoreDNS pods.
Focusing on Root Cause & Possible Options
When it comes to caching DNS queries, most of the documentations (including Kubernetes official documentation)refers to using NodeLocal DNS cache.
Unfortunately It is common between technical people to jump on “the other solution” at each problem, instead of understanding the root cause and fixing it. With NodeLocal DNS architecture, we simply install a Daemonset (a DNS pod at each node) and making changes at “kubelet”, we enforce pods to connect to a DNS pod, hosted at the same node with application pod and cache the queries there. The problem with this approach is;
- Daemonset deploys only one DNS pod and in case of a failure, until Kubernetes deploys a new pod, all queries fail.
- Similar with the previous one, in case of a high load,
Daemonsetis not designed to scale up, deployment size is static, one pod per node.
- Besides from that, CoreDNS also has caching feature as plugin.
- And most importantly, latency gain between connecting a CoreDNS pod at another node and connecting to one at the same node is around 0.8ms, I would be surprised if an application suffers from this latency.
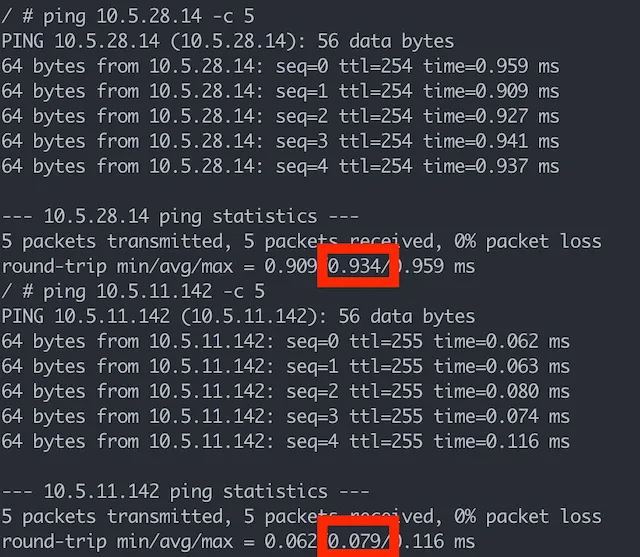
So basically, NodeLocal DNSCache is not solving the problem described in this post.
Turning back to our effort to found root cause of high DNS load, we started wondering why pods are resolving same DNS queries every-time.
ndot (searching domains locally or externally)
In order to understand why each DNS lookup goes to external system (outside pod, not outside Kubernetes), It’s important to understand how DNS lookups work at Kubernetes. Let’s look at “/etc/resolv.conf” file again;

On the Linux systems, when a DNS query required, search is done through local search domains or as an external domain. So, searching it locally or externally all depends on whether this domain is fully qualified domain name “FQDN” or local domain. And “ndot” parameter defines whether a domain is a fully qualified domain or local domain.
Looking at our example database endpoint domain; “dbname.randomstring.eu-west-1.rds.amazonaws.com” It’s a FQDN, but if it’s not knows as local domain at each query will be search locally using CoreDNS, causing high load at CoreDNS pods and latency.
What determines a domain is being FQDN or local domain is “ndot” parameter inside “/etc/resolv.conf” file. As it can be seen at the snippet given at the beginning, at EKS, this value is 5
Based on the documentation from “ndot”
ndots:n
sets a threshold for the number of dots which must appear in a name before an initial absolute query will be made. The default for n is 1, meaning that if there are any dots in a name, the name will be tried first as an absolute name before any search list elements are appended to it.
So the problem is, as our database endpoint has 4 dots, each pod considers database endpoint not as an FQDN, querying it to DNS server(CoreDNS) and CoreDNS searches each domain as local domain inside the cluster first and then finally queries external DNS servers.
Solution and Considerations
As the root cause is determined, there are couple of options in order to solve this problem.
If our domains had 5 dots, then it’ll be considered as fully qualified name and search externally, for all other domains, It’ll go through local domain search then it’ll resolve it as absolute name.
So “ndots” can be change either via kubelet, at the pod level using spec.dnsConfig parameter or making all domain fully qualified names adding “dot” parameter at the end of the string.
Solution 1: Enforcing “ndot” parameter from “kubelet”
Using “ — resolv-conf string” parameter at kubelet configuration, ndot parameter can be adjusted. The problem here is, at the time of writing this post, EKS doesn’t support adjusting kubelet parameters at Node Group setup, so you have to manage EKS nodes by yourself using AWS Autoscaling Groups.
Solution 2: Adjust “spec.dnsConfig” parameter at each pod level
It’s possible to adjust “ndot” parameter at each pod/deployment definition like below. As it’s an infrastructure related problem, not something related with application, also considering the possibility of forgetting this parameter at new projects, it’s not the best place to have it.

Solution 3: Explicitly specifying Fully Qualified Domain Names with “dot” at the end.
Ending a domain name with “dot” character explicitly specify that this domain is “Fully Qualified Domain Name” (FQDN), meaning that DNS resolve process won’t go through full local domain search process, It’ll be cached at CoreDNS and it won’t go outside the Kubernetes cluster.
As an example, as a database endpoint, instead of;
“dbname.randomstring.eu-west-1.rds.amazonaws.com”
if we use;
“dbname.randomstring.eu-west-1.rds.amazonaws.com.”
It’ll be considered as FQDN by Pods and CoreDNS.
Extra Improvement:
“everything fails all the time!”
If any DNS query fails because of CoreDNS pod issue or connectivity from application pod to CoreDNS pod, application pods should try at least a couple of more times.
It’s possible via using Pod “spec.dnsConfig” parameter.

With this configuration at the pod manifest, when a Pod fails to receive a DNS query result, It’ll retry again and most probably hit another CoreDNS pod inside the Kubernetes cluster.
We provide AWS and Kubernetes 24/7 services. Feel free to reach out.
Resources:
https://en.wikipedia.org/wiki/Fully_qualified_domain_name
https://kubernetes.io/docs/tasks/administer-cluster/nodelocaldns/
https://www.weave.works/blog/racy-conntrack-and-dns-lookup-timeouts
https://coredns.io/2018/11/15/scaling-coredns-in-kubernetes-clusters/
https://aws.amazon.com/premiumsupport/knowledge-center/eks-dns-failure/




